![[MQ] RabbitMQ 클러스터링(Clustering)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcadihU%2Fbtsc2m3Xjaa%2FaUK8SNT0mEqgrMm6s3KWA1%2Fimg.png)
혹시 RabbitMQ에 대한 이해가 필요하시다면 여기를 먼저 보고와주세요!
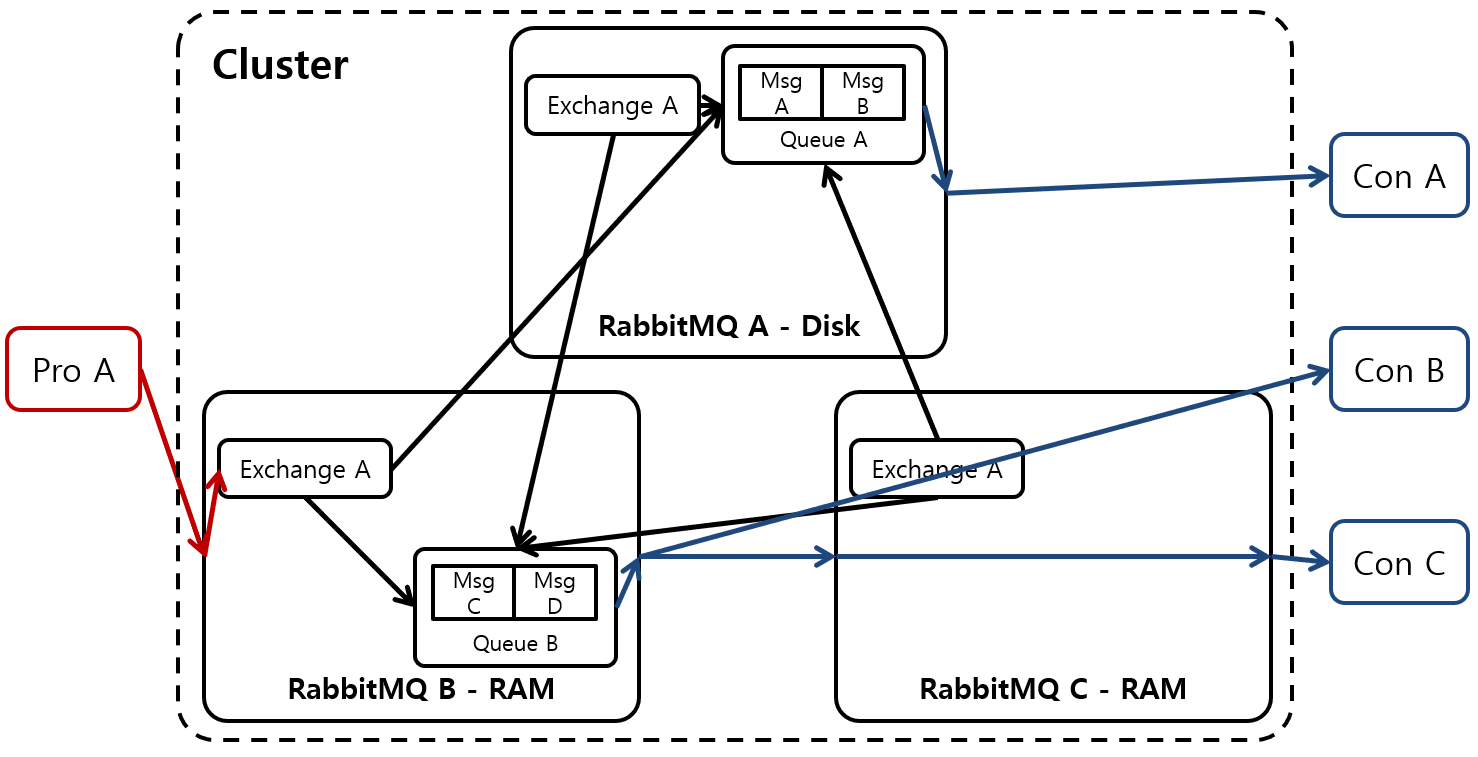
RabbitMQ 클러스터링이란?
다수의 RabbitMQ 노드(RabbitMQ가 설치된 서버)를 마치 하나의 RabbitMQ를 사용하는 것처럼 사용할 수 있는 기법입니다. 위 그림처럼 클러스터에 노드가 3개 존재한다면 어떤 노드에 연결해도 나머지 두 개 노드의 RabbitMQ에 접근할 수 있습니다.
어떻게 그게 가능한가요?
클러스터에 구성된 RabbitMQ들은 Queue를 제외한 모든 정보와 상태값이 공유됩니다*. 예시로 Exchange 같은 경우 클러스터내에 있는 모든 RabbitMQ에 동일하게 존재합니다. 따라서 하나의 노드에만 connection이 맺어져있어도 노드가 queue를 보유하고있는지 상관없이 원하는 Exchange를 통해 원하는 Queue로 메시지를 전송할 수 있습니다.
*Queue를 제외한 정보가 공유된다는 말은 곧 노드의 생성된 하나의 Queue는 모든 클러스터에서 하나만 존재한다는 뜻이기도 합니다.
Erlang Cookie
클러스터에 속한 노드들은 Erlang Cookie라는 비밀 쿠키 파일을 통해 서로 통신해도 되는지에 대해서 파악합니다. Erlang Cookie는 단순 alphanumeric 으로 이루어진 String 값으로 이루어져있고 주로 노드의 로컬 저장소에 저장됩니다. 클러스터에 소속된 노드들은 같은 Erlang Cookie를 가지고 있어야만 서로 통신이 가능하기 때문에 모든 노드들이 반드시 같은 쿠키 파일을 가지고 있어야합니다.
모든 노드의 역할이 동일하다 (특정 플러그인을 사용하지 않을 경우)
k8s 나 Elasticsearch 같은 분산 시스템의 경우 leader-follower 구조로 되어있는 경우들을 보신적이 있으실겁니다 (예: 마스터 노드 하나가 나머지 노드들을 관리하는 경우). RabbitMQ 클러스터는 이들과 다르게 모든 노드가 동일한 역할을 가지고 있습니다. 따라서 HTTP API 클라이언트는 어떤 클러스터 노드와 연결되어도 상관없습니다.
하지만 특정 플러그인, 예를들어 federation plugin(다른 RabbitMQ cluster 간의 통신을 도와주는 플러그인) 이 설치된 노드의 경우 해당 노드만의 역할이 정해져있으므로, 클러스터에서 해당 노드가 fail하게 되면 임의의 다른 노드가 해당 역할을 물려받게됩니다.
다 같으면 producer와 comsumer는 어느 노드에 연결해야되나요?
위 설명을 보시면 아시겠지만 둘다 어느 노드에 연결해도 상관없습니다. 심지어 producer와 consumer가 서로 같은 노드를 바라볼 필요도 없습니다. 하지만 그렇다고 하나의 노드에 모든 연결을 하게되면 클러스터링의 의미가 없고 HA가 불가능하겠죠. 따라서 일반적으로 클라이언트와 클러스터 사이에 Load Balancer를 두어서 하나의 노드에 몰리거나 노드 하나가 fail하더라도 계속해서 클러스터와 connection을 유지할 수 있도록 해줍니다.
클러스터 노드 개수는 몇 개로 해야되나요?
노드의 개수는 3개 이상을 추천하고 가능하면 홀수개를 추천합니다. 특히 노드 2개는 RabbitMQ에서 대놓고 추천하지 않는다고 경고를 해놓았습니다. 그 이유는 노드에 특정 기능(quorum queue, client tracking in MQTT)이 포함돼있는 상태라면 있는 노드 중 majority를 파악하거나 connection fail 상황에서 투표를 해야하는데 노드가 2개라면 투표가 진행될 수 없기 때문입니다. 짝수일 경우에도 동일한 표가 나올 수 있기 때문에 노드 개수는 홀수가 추천됩니다.
노드가 여러개면 클러스터에 대한 통계는 어떻게 보죠?
각 노드는 자신의 metric과 stats를 저장하고 종합합니다. 그리고 다른 노드가 이 정보를 조회할 수 있도록 API를 제공합니다. 따라서 하나의 노드에서도 나머지 노드에 대항 정보를 종합해서 통계를 보여줄 수 있습니다. (아주 예전 버전에서는 management plugin 을 사용하여 한개 노드에서 모든 통계 정보를 저장하기도 했었습니다.)
클러스터 구성 방법
- RabbitMQ cli (rabbitmqctl)를 사용해서 수동 구성
- config 파일 설정을 사용하여 구성
- DNS-based discovery 를 사용해서 구성
- AWS instance discovery 를 사용해서 구성 (플러그인 사용)
- Kubernetes discovery 를 사용하여 구성 (플러그인 사용)
- Consul-based discovery 를 사용하여 구성 (플러그인 사용)
- etcd-based discovery 를 사용하여 구성 (플러그인 사용)
(자세한 구성 방법은 실습편에서 다루겠습니다)
클러스터 확장 방법
RabbitMQ 클러스터는 동작 중에도 중단없이 새로운 노드를 추가할 수 있습니다. Peer Discovery Plugin 을 통해서 클러스터에 소속된 RabbitMQ 노드를 자동으로 발견하고 Clustering 까지 수행합니다. 한가지 주의할 점은 새로운 RabbitMQ 노드가 추가되어도 해당 노드에 Queue가 존재하지 않는다면 새로운 RabbitMQ로는 부하분산이 제대로 이루어지지 않을 수 있습니다. 따라서 Cluster에 RabbitMQ가 추가된 뒤에는 Queue Rebalancing을 통해 클러스터 부하를 분산시켜야 합니다.
Queue Rebalancing 이란?
RabbitMQ 클러스터는 기본적으로 부하를 최대한 분산(모든 노드가 비슷한 workload를 가지도록)시켜서 최고의 효율을 내는 것을 목적으로 합니다. 따라서 클러스터 내 노드가 증가하거나 감소할때마다 전체 Queue가 모든 노드에 비슷하게 분산되도록 해주는 것이 queue rebalancing 입니다. Rebalancing을 수행하는 방법은 RabbitMQ에서 제공하는 스크립트나 Third-party Plugin을 활용할 수도 있습니다.
출처:
- https://www.rabbitmq.com/clustering.html
- RabbitMQ Clustering, Mirroring
'Programming' 카테고리의 다른 글
| [k8s] containerd란? 쿠버네티스와의 관계 (0) | 2024.07.08 |
|---|---|
| [MQ] RabbitMQ 미러링(Mirroring) (0) | 2023.05.01 |
| [클라우드] 오픈스택(OpenStack) 이란? (0) | 2023.04.15 |
| [MQ] RabbitMQ 란? (0) | 2023.04.11 |
| [보안] SHA 암호화 알고리즘 (0) | 2022.11.01 |